Table of contents
MCP란 무엇인가
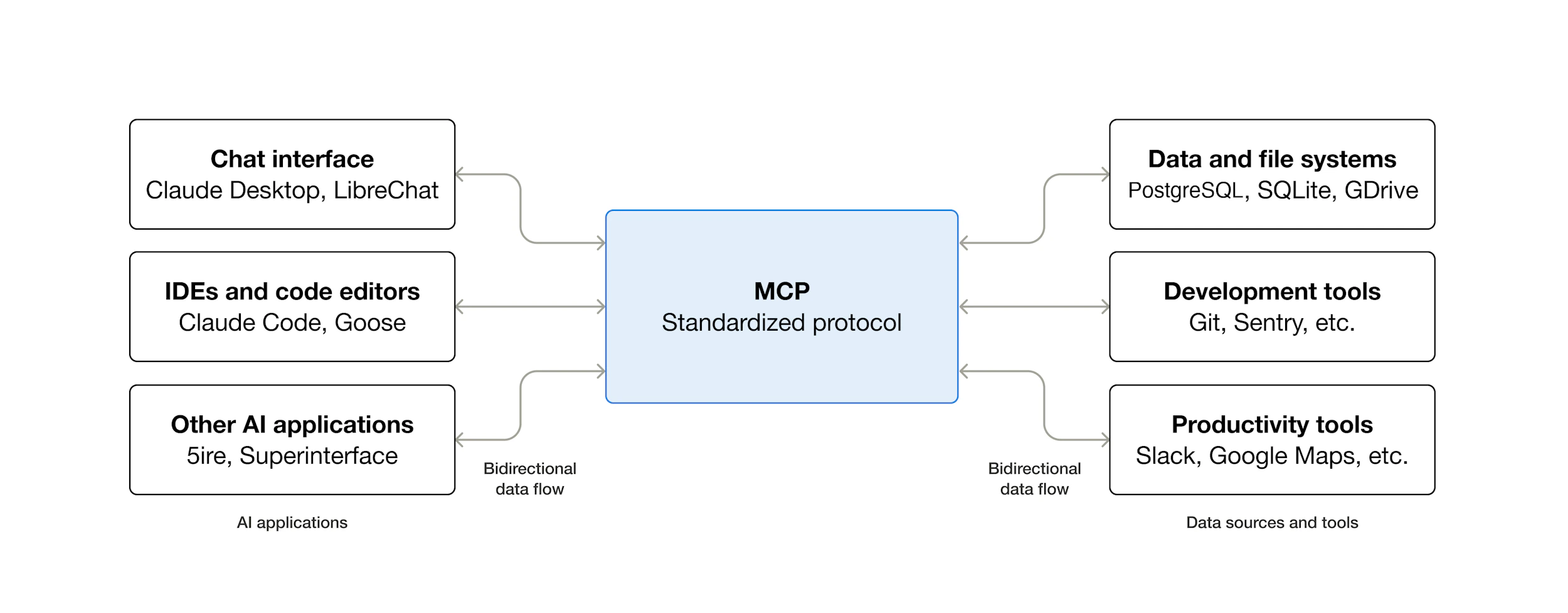
MCP(Model Context Protocol)는 AI 애플리케이션이 외부 데이터·도구와 연결되는 방식을 표준화한 오픈 프로토콜이다.
쉽게 말해, AI에 외부 데이터·도구를 끼우는 공용 어댑터다. USB-C 한 가지로 여러 기기가 이어지듯, MCP 한 가지로 여러 AI 도구와 여러 데이터 소스가 이어진다.
출처: Model Context Protocol 공식 문서
Anthropic이 2024년 11월에 공개했다. Claude Desktop이 외부 데이터를 잘 끌어다 쓰게 하려는 내부 과제로 출발했지만, 처음부터 오픈 프로토콜로 설계해 spec과 SDK를 GitHub에 같이 공개했다. 2025년 한 해에 spec이 빠르게 다듬어졌다. 6월엔 인증 표준으로 OAuth 2.1이 들어왔고, 11월엔 Streamable HTTP 트랜스포트가 정식이 되어 그 전에 쓰던 SSE 기반 트랜스포트를 대체했다. 2026년 공식 로드맵의 큰 줄기는 stateless 운영, 에이전트 간 통신, 엔터프라이즈 도입(SSO·감사 로그)이다.
호스트 쪽 채택도 같이 늘었다. Claude Desktop·Claude Code는 기본 지원이고 Cursor, VS Code, Continue, Goose, Zed가 이미 MCP 클라이언트로 동작한다. 서버 쪽은 공식 참고 구현 리포에 수십 개가 있고, 회사·개인이 만든 것까지 합치면 1년 반 만에 사실상 업계 공용 규격이 됐다.
“표준화한 프로토콜”이라는 말은 들어도 그림이 잘 안 그려진다. 가장 단순한 시나리오부터 본다. Claude Desktop을 깔고 작업한다고 하자. 평소에 자주 만지는 ~/projects/my-app 폴더가 있고, 그 안의 파일을 Claude가 직접 읽어서 수정 제안을 해주면 좋겠다.
가장 단순한 방법은 복사 붙여넣기다. 파일을 열어 채팅창에 붙이고 질문한다. 파일이 많으면 토큰이 폭발하고, 답을 받으면 다음 질문에선 또 붙여 넣어야 한다.
다른 방법이 있다. Filesystem MCP 서버라는 작은 프로그램을 깔고, Claude Desktop의 설정 파일에 이 서버를 등록한다. 그 순간부터 Claude는 자기 도구 목록에 파일 읽기, 디렉터리 목록 보기, 파일 쓰기 같은 함수를 자동으로 갖는다.
사용자가 “내 프로젝트 src 폴더 한번 봐줘”라고 말하면, Claude가 내부적으로 list_directory("/Users/me/projects/my-app/src") 같은 호출을 만든다. MCP 서버가 그걸 받아 실제 디렉터리를 읽고 결과를 돌려준다. Claude는 그 결과를 바탕으로 답한다. 사용자는 함수를 직접 부르지 않았다 — 자연어로 부탁했을 뿐이다.
flowchart LR
classDef host fill:#4a90d9,color:#fff,stroke:#2c5d8f
classDef server fill:#5ca45c,color:#fff,stroke:#3d7a3d
classDef data fill:#7f8c8d,color:#fff,stroke:#4d5656
U[사용자] -->|"src 폴더 봐줘"| H[Claude Desktop]:::host
H <-->|MCP 프로토콜| S[Filesystem<br/>MCP Server]:::server
S <-->|읽기·쓰기| F[로컬 파일시스템]:::data
H --> U이 흐름에 두 가지가 박혀 있다. Claude(호스트)와 Filesystem 서버는 따로 만들어졌고 서로 잘 알지 못한다. 그저 MCP라는 공통 규칙으로 대화한다. 그리고 사용자는 함수를 직접 부르지 않았다. Claude가 알아서 적절한 도구를 골라 호출했다.
Filesystem 자리에 다른 서버를 끼우면 같은 흐름으로 다른 통합이 된다.
| MCP 서버 | Claude가 갖게 되는 도구 |
|---|---|
| Filesystem | 파일 읽기·쓰기, 디렉터리 목록 |
| GitHub | PR 조회, 이슈 검색, 커밋 내역 |
| Sentry | 에러 조회, 이슈 그룹화 |
| Postgres | 스키마 조회, 안전한 쿼리 실행 |
| Slack | 채널 메시지 조회, 검색 |
| 사내 위키 | 문서 검색, 페이지 읽기 |
서버를 만든 사람은 다 다르다. Anthropic이 만든 것도, GitHub·Sentry처럼 회사가 직접 만든 것도, 개인이 오픈소스로 공개한 것도 있다. 그래도 Claude Desktop은 셋 다 똑같이 받아 쓴다. 새 서버가 나와도 Claude를 고칠 일이 없다.
호스트 쪽도 마찬가지다. Filesystem 서버 하나를 만들어두면 Claude Desktop이든 Cursor든 VS Code든 MCP를 말할 줄 아는 어떤 도구든 그 서버를 쓴다. 한 번 만든 통합이 어디든 붙는다는 게 표준의 가치다.
Host, Client, Server
여기까지는 “Claude Desktop이 Filesystem 서버에 붙는다” 정도로만 그렸다. 사용자 시선에선 그 정도면 충분한데, spec을 들여다보면 그 사이에 Host, Client, Server라는 세 가지 역할이 따로 정의되어 있다.
Host (호스트) — AI 애플리케이션 자체다. 사용자와 대화하고, LLM에게 무엇을 보낼지 정하고, 여러 서버에서 받아온 컨텍스트를 조합하고, “이 툴 호출해도 되겠나?” 같은 동의 화면을 책임진다. 위 예시의 Claude Desktop이 호스트다. Cursor·VS Code·Claude Code도 같은 자리의 호스트다.
Client (클라이언트) — 호스트 안에 살면서 서버 하나당 하나씩 만들어지는 작은 커넥터다. 자기에게 묶인 서버 하나하고만 평생 대화한다. Claude Desktop이 Filesystem 서버에 붙는 순간, 그 연결을 전담하는 Filesystem 전용 클라이언트 하나가 호스트 안에 생긴다. 같은 사용자가 GitHub 서버까지 같이 쓰면 GitHub 전용 클라이언트가 별도로 또 생긴다.
Server (서버) — 데이터·도구를 제공하는 외부 프로그램이다. Filesystem 서버, GitHub 서버, Sentry 서버, 사내 자체 서버 같은 것들. 호스트와 같은 컴퓨터에서 자식 프로세스로 돌 수도 있고, 인터넷 너머의 SaaS로 떠 있을 수도 있다.
flowchart TB
classDef host fill:#4a90d9,color:#fff,stroke:#2c5d8f
classDef client fill:#3a9d8f,color:#fff,stroke:#266b62
classDef server fill:#5ca45c,color:#fff,stroke:#3d7a3d
subgraph H["Host (Claude Desktop, Cursor, VS Code 등)"]
direction LR
C1[Filesystem<br/>Client]:::client
C2[GitHub<br/>Client]:::client
C3[Sentry<br/>Client]:::client
end
H:::host
S1[Filesystem<br/>Server]:::server
S2[GitHub<br/>Server]:::server
S3[Sentry<br/>Server]:::server
C1 <--> S1
C2 <--> S2
C3 <--> S3호스트 1개, 클라이언트 N개, 서버 N개. 클라이언트와 서버는 1:1로 묶인다.
분리한 이유는 단순하다. 클라이언트가 서버 하나만 보면, 한 서버가 죽거나 권한 만료로 끊겨도 다른 서버 연결이 멀쩡하다. 서버마다 다른 인증 토큰·권한 범위를 클라이언트 단위로 격리해 관리할 수도 있다. 호스트는 N개 클라이언트가 가져온 결과를 모아 LLM 컨텍스트로 합친다 — 어떻게 합칠지는 호스트가 알아서 정한다.
한 가지 더. “서버”는 위치가 아니라 역할이다. 같은 머신의 다른 프로세스로 돌든(stdio), 인터넷 너머의 클라우드 서비스로 돌든(HTTP), MCP에선 둘 다 서버다. Claude Desktop이 로컬 Filesystem 서버를 자식 프로세스로 띄워 쓰는 것과 원격 Sentry MCP 서버에 HTTPS로 붙는 것이 같은 spec 위에서 일어난다.
데이터 층과 트랜스포트 층
세 역할이 잡혔으면 그 사이를 흐르는 프로토콜을 한 칸 안으로 들어가본다. MCP는 두 층으로 갈라져 있다.
flowchart TB
classDef data fill:#4a90d9,color:#fff,stroke:#2c5d8f
classDef tr fill:#8e6abf,color:#fff,stroke:#5d4485
subgraph Outer["Transport Layer (어떻게 주고받느냐)"]
direction LR
T1[stdio<br/>로컬 프로세스 사이]:::tr
T2[Streamable HTTP<br/>원격 서버]:::tr
end
subgraph Inner["Data Layer (무엇을 주고받느냐)"]
direction TB
L1["JSON-RPC 2.0<br/>메시지 형식"]:::data
L2["Lifecycle<br/>연결·capability 협상·종료"]:::data
L3["Primitives<br/>서버: Tools / Resources / Prompts<br/>클라이언트: Sampling / Roots / Elicitation"]:::data
end
Outer --> Inner데이터 층은 무엇을 주고받느냐를 정한다. 메시지는 JSON-RPC 2.0 형식이고, 그 위에서 lifecycle(연결 시작, capability 협상, 종료)과 primitives가 정의된다. 클라이언트와 서버가 만나면 먼저 서로 어떤 기능을 지원하는지 알리는 인사말(initialize)을 주고받고, 그 결과로 정해진 능력 안에서 이후 메시지가 흐른다.
트랜스포트 층은 그 메시지를 어떻게 전달하느냐를 정한다. 같은 머신의 다른 프로세스라면 표준 입출력으로 주고받는 stdio를, 인터넷 너머라면 Streamable HTTP를 쓴다. Streamable HTTP는 2025년 11월 spec부터 정식이고, 그 전의 SSE 기반 트랜스포트를 대체한다.
이렇게 갈라둬서 같은 데이터 층 메시지가 stdio든 HTTP든 그대로 흐른다. 서버를 로컬용으로 만들었다가 원격으로 옮기는 작업이 트랜스포트 교체 한 번으로 끝나고, 인증·세션 같은 트랜스포트 관심사가 메시지 모양으로 새지 않는다.
Primitives
데이터 층에서 손에 가장 자주 닿는 게 primitives다. 서버가 클라이언트에게 노출하는 게 셋, 클라이언트가 서버에게 노출하는 게 셋이다. 여기서는 이름과 역할만 짚는다.
서버 → 클라이언트 (서버가 제공)
| Primitive | 무엇을 노출하나 | 예시 |
|---|---|---|
| Tools | LLM이 호출할 수 있는 함수 | DB 쿼리, 파일 쓰기, API 호출 |
| Resources | LLM이나 사용자가 읽을 수 있는 데이터 | 파일 내용, DB 레코드, 페이지 본문 |
| Prompts | 사용자가 호출할 수 있는 템플릿/워크플로우 | ”이슈 정리해줘” 같은 슬래시 명령 |
클라이언트 → 서버 (호스트가 제공)
| Primitive | 무엇인가 | 언제 쓰나 |
|---|---|---|
| Sampling | 서버가 호스트의 LLM을 빌려 쓴다 | 서버에 LLM SDK를 넣고 싶지 않을 때 |
| Roots | 서버가 작업할 수 있는 경로/URI 범위 | 파일시스템 서버에 “이 디렉터리만 봐”라고 알릴 때 |
| Elicitation | 서버가 사용자에게 추가 정보를 묻는다 | ”정말 삭제할까요?” 확인, 누락 파라미터 입력 |
각 primitive에는 표준 메서드 패턴이 있다. 발견(tools/list, resources/list), 조회·실행(resources/read, tools/call), 그리고 변경 시 푸시되는 알림(notifications/tools/list_changed). 클라이언트는 연결 직후 tools/list를 불러서 서버가 노출한 도구를 알아내고, 그걸 LLM의 도구 카탈로그에 합쳐 모델에게 제시한다.
MCP가 정하지 않는 것
MCP의 표준 범위는 좁다.
- LLM이 컨텍스트를 어떻게 쓰느냐에는 관여하지 않는다. 호스트가 받아온 데이터를 시스템 프롬프트에 박을지, RAG처럼 일부만 끌어쓸지는 호스트의 선택이다.
- 모델 선택과 무관하다. Claude를 쓰든 GPT를 쓰든, 호스트가 MCP 클라이언트를 구현해두기만 하면 같은 서버를 쓴다.
- UI/UX 결정권은 호스트에 있다. “이 툴 호출해도 되겠나” 묻는 화면을 어떻게 그릴지 MCP는 정하지 않는다.
범위가 좁다는 게 장점이다. 모델·호스트·서버가 각자 발전하면서도 사이의 연결 규칙만 표준이라 깨질 일이 적다.
다음 편에서는 서버가 클라이언트에게 노출하는 Tools, Resources, Prompts 셋을 깊이 본다. 각각이 어떤 메서드 패턴(*/list, */get, */call)을 쓰고, inputSchema는 어떻게 정의하며, 셋을 언제 골라 쓰느냐가 서버 설계의 첫 분기점이다.




Loading comments...